
|
MatricesPhilip J. ErdelskyMarch 23, 2009 |
Please e-mail comments, corrections and additions to the webmaster at pje@efgh.com.
|
|
MatricesPhilip J. ErdelskyMarch 23, 2009 |
Please e-mail comments, corrections and additions to the webmaster at pje@efgh.com.
A matrix is a rectangular array of numbers, called its entries, which are arranged into one or more rows and columns, such as the following:
∣ 1 8 5 7 1 ∣
A = ∣ 2 6 6 12 3 ∣
∣ 4 5 -5 0 -9 ∣
x = ∣ 4 5 -3 ∣
The vertical lines at the sides of the matrices may appear broken on some browsers; they are normally intact.
The entries are usually taken from a field, but matrices over more general spaces, such as commutative rings, are possible, and some results will apply to them, too.
Numbers in the field or other space from which matrix entries are taken are called scalars.
Two matrices are equal only if they have the same number of rows, the same number of columns, and equal entries in corresponding positions.
A matrix is conventionally represented by a boldface capital letter. However, a matrix with only one row is called a row vector, a matrix with only one column is called a column vector, and both may be represented by boldface small letters.
A matrix with m rows and n columns is said to be an m ⨯ n matrix. Notice that the number of rows comes first; this is the conventional order. For example, the matrix A is a 3 ⨯ 5 matrix, and x is a 1 ⨯ 3 row vector.
A matrix with the same number of rows and columns is called, not surprisingly, a square matrix.
The rows of an m ⨯ n matrix are conventionally numbered from 1 to m, where row 1 is at the top and row m is at the bottom. The columns are conventionally numbered from 1 to n, where column 1 is on the left side and column n is on the right side. Individual rows and columns of a matrix are often treated as row and column vectors.
The entry in the i-th row and the j-th column of a matrix A is conventionally represented by ai,j (or aij if the comma is not needed to prevent ambiguity), using the corresponding small letter without boldface. Notice that the row number comes first; this is the conventional order.
Some computer languages, such as C, implement vectors or matrices with row and column numbers beginning with 0 instead of 1. This corresponds more closely to the internal representation of data in computer memories, but care must be taken to avoid off-by-one errors when programming operations defined with the standard numbering.
The transpose of an m ⨯ n matrix A is the n ⨯ m matrix AT obtained by interchanging the rows and columns of A:
B = AT, bij = aji.
For example, the transposes of the matrices defined above are given by
∣ 1 2 4 ∣
∣ 8 6 5 ∣
AT = ∣ 5 6 -5 ∣
∣ 7 12 0 ∣
∣ 1 3 -9 ∣
∣ 4 ∣
xT = ∣ 5 ∣
∣-3 ∣
This notation is convenient when column vectors such as (4,5,-3)T are embedded in running text.
If A is matrix and s is a scalar, then the product sA is a matrix P with the same number of rows and columns as A, obtained by multiplying every entry in A by s:
P = sA, pij = saij.
If A and B are two matrices with the same number of rows, the same number of columns, and entries from the same field, the sum A + B is a matrix T with the same numbers of rows and columns as A or B, obtained by adding corresponding entries in A and B:
T = A + B, tij = aij + bij.
Notice that for row or column vectors, these definitions are consistent with the vector operations defined elsewhere. In fact, the set of m ⨯ n matrices can be construed as a vector space of dimension mn. Accordingly, matrix addition and scalar multiplication obey the same commutative, associative and distributive laws as the corresponding vector operations, and some others, too:
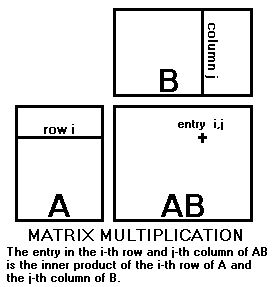
Let A be an m ⨯ r matrix and let B be an r ⨯ n matrix, with entries from the same field, Then the product AB is an m ⨯ n matrix C defined by:
C = AB, cij = ai1 b1j + ai2 b2j + ... + air brj.
Notice that the entry in the i-th row and j-th column of the product is formed by multiplying the entries in the i-th row of the first matrix by the corresponding entries in the j-th column of the second matrix and adding the products. This is in fact the same as the definition of the inner product of two vectors.
Matrix multiplication has the following properties, where A and B are matrices of appropriate shapes and s is a scalar:
All of these properties can be derived directly from the definition of matrix multiplication. However, deriving the associative law in this way is fairly difficult; it will be demonstrated later by other means.
Matrix multiplication is not commutative. Even if AB and BA are both defined, they are not necessarily equal. For example, if x and y are 3 ⨯ 1 column vectors, then xTy and yxT are both defined, but the former is a 1 ⨯ 1 matrix, and the latter is a 3 ⨯ 3 matrix. Even if A and B are square, so that AB and BA are the same size, the two products may be unequal:
∣ 0 1 ∣ ∣ 0 0 ∣ ∣ 0 1 ∣ ∣ ∣ ∣ ∣ = ∣ ∣ ∣ 0 0 ∣ ∣ 0 1 ∣ ∣ 0 0 ∣ ∣ 0 0 ∣ ∣ 0 1 ∣ ∣ 0 0 ∣ ∣ ∣ ∣ ∣ = ∣ ∣ ∣ 0 1 ∣ ∣ 0 0 ∣ ∣ 0 0 ∣
Therefore, the set of all square matrices of a particular size (2 ⨯ 2 or larger) is seen to be a noncommutative ring.
This example also shows that multiplication of two nonzero matrices may produce a zero result.
There is no cancellation law for matrix multiplication; i.e., AB = CB does not necessarily imply that A = C. However, it is easy to show that if AB = CB for all B of a particular size and shape, then A = C.
Some special cases of matrix multiplication are worth noting.
If x and y are n ⨯ 1 column vectors, then xTy is essentially the inner product defined elsewhere. (Technically, it is the 1 ⨯ 1 matrix whose sole entry is the inner product.)
The principal diagonal or main diagonal of a matrix consists of all entries whose row and column numbers are the same; i.e., the main diagonal entries of A are a11, a22, a33, etc. All other entries are called off-diagonal entries. A diagonal matrix is a square matrix whose off-diagonal entries are all zeros. Multiplication by a square diagonal matrix gives a particularly simple result. If D is a square diagonal matrix, then DA is the matrix A with each row multiplied by the main diagonal entry in the corresponding row of D, and AD is the matrix A with each column multiplied by the main diagonal entry in the corresponding column of D.
A square diagonal matrix in which every diagonal entry is 1 is called the identity matrix and is usually written as I because IA = A and BI = B for any matrices A and B with the proper number of rows or columns.
In some proofs, we will have to multiply one row of a matrix by a scalar and add it to another row, a process which is called an elementary row operation. If A is any matrix, there is a square matrix E(i,j,c) with the same number of rows as A such that E(i,j,c)A is the matrix A after multiplying the i-th row by c and adding it to the j-th row. The matrix E(i,j,c) is the identity matrix in which eji has been replaced by c.
A matrix can be partitioned into smaller matrices by drawing horizontal and vertical lines through it, as in the following examples:
∣ 1 1 ∣ 0 1 ∣ ∣ 1 1 ∣ ∣ 1 1 ∣ 0 0 ∣ ∣ 2 2 ∣ ------------- ------- ∣ 0 0 ∣ 1 0 ∣ ∣ 4 1 ∣ ∣ 0 1 ∣ 0 1 ∣ ∣ 1 4 ∣
These matrices can be interpreted either as 4 ⨯ 4 and 4 ⨯ 2 matrices of real numbers, or as 2 ⨯ 2 and 2 ⨯ 1 matrices whose entries are 2 ⨯ 2 matrices of real numbers.
If we multiply the large matrices in the usual way, we obtain
∣ 1 1 0 1 ∣ ∣ 1 1 ∣ ∣ 4 7 ∣ ∣ 1 1 0 0 ∣ ∣ 2 2 ∣ = ∣ 3 3 ∣ ∣ 0 0 1 0 ∣ ∣ 4 1 ∣ ∣ 4 1 ∣ ∣ 0 1 0 1 ∣ ∣ 1 4 ∣ ∣ 3 6 ∣
If we multiply the large matrices, treating the smaller matrices as entries in the large matrices, we obtain
∣ 1 1 ∣ 0 1 ∣ ∣ 1 1 ∣ ∣ 1 1 ∣ 0 0 ∣ ∣ 2 2 ∣ ------------- ------- = ∣ 0 0 ∣ 1 0 ∣ ∣ 4 1 ∣ ∣ 0 1 ∣ 0 1 ∣ ∣ 1 4 ∣ ∣ ∣ 1 1 ∣ ∣ 1 1 ∣ ∣ 0 1 ∣ ∣ 4 1 ∣ ∣ ∣ ∣ 1 1 ∣ ∣ 2 2 ∣ + ∣ 0 0 ∣ ∣ 1 4 ∣ ∣ ------------------------------------- ∣ ∣ 0 0 ∣ ∣ 1 1 ∣ ∣ 1 0 ∣ ∣ 4 1 ∣ ∣ ∣ ∣ 0 1 ∣ ∣ 2 2 ∣ + ∣ 0 1 ∣ ∣ 1 4 ∣ ∣
Now we use regular matrix operations on the smaller matrices to obtain a matrix of matrices:
∣ ∣ 3 3 ∣ ∣ 1 4 ∣ ∣ ∣ ∣ 4 7 ∣ ∣ ∣ ∣ 3 3 ∣ + ∣ 0 0 ∣ ∣ ∣ ∣ 3 3 ∣ ∣ --------------------- = ----------- ∣ ∣ 0 0 ∣ ∣ 4 1 ∣ ∣ ∣ ∣ 4 1 ∣ ∣ ∣ ∣ 2 2 ∣ + ∣ 1 4 ∣ ∣ ∣ ∣ 3 6 ∣ ∣
This is the result obtained by regular matrix multiplication, partitioned into two smaller matrices.
This is true for any other way of partitioning matrices, provided the partitions are consistent. The partition theorem for matrix multiplication can be stated more formally.
Theorem 3.1. Let A be an m ⨯ r matrix and let
B be an
r ⨯ n matrix, with entries from the same field. Let A, B and
AB be partitioned so that
Then the submatrices of AB may be computed by the rules of matrix
multiplication
on the submatrices of A and B, using regular matrix addition and
multiplication on the submatrices.
Proof. The entry in the i-th row and j-th column of AB is the inner product of the i-th row of A and j-th column of B. Because of the ways the matrices are partitioned, the entry lies in the submatrix computed using the row and column of submatrices in A and B, respectively, used to compute the entry.
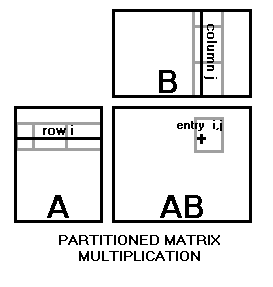
Moreover, its row and column number in the submatrix are equal to the row and column numbers of the i-th row and j-th column in the submatrices that they pass through. Hence the computation using submatrices uses the same products as the direct computation, summed piecemeal. Since addition is associative, the result is the same. █
The partition theorem for matrix addition and scalar multiplication is fairly obvious.
Theorem 3.2. Let A and B be m ⨯ n matrices, with entries from the same field, and let s be a scalar. Let A, B, sA and A+B be partitioned so that the same partition is applied to the rows of each matrix, and the same partition is applied to the columns of each matrix. Then each submatrix in sA can be found by multiplying the corresponding submatrix in A by s, and each submatrix in A+B can be found by adding the corresponding submatrices in A and B.
Now let us reconsider the associativity of matrix multiplication. For general 2 ⨯ 2 matrices, we can verify associativity directly:
∣ a b ∣ ∣ c d ∣ ∣ e f ∣ ∣ ac+bi ad+bj ∣ ∣ e f ∣ ∣ ace+bie+adk+bjk acf+bif+adl+bjl ∣ ∣ g h ∣ ∣ i j ∣ ∣ k l ∣ = ∣ gc+hi gd+hj ∣ ∣ k l ∣ = ∣ gce+hie+gdk+hjk gcf+hif+gdl+hjl ∣ ∣ a b ∣ ∣ c d ∣ ∣ e f ∣ ∣ a b ∣ ∣ ce+dk cf+dl ∣ ∣ ace+adk+bie+bjk acf+adl+bif+bjl ∣ ∣ g h ∣ ∣ i j ∣ ∣ k l ∣ = ∣ g h ∣ ∣ ie+jk if+jl ∣ = ∣ gce+gdk+hie+hjk gcf+gdl+hif+hjl ∣
This is valid if addition of matrix entries is commutative and multiplication of matrix entries is associative and distributes over addition. This is certainly true if the entries are taken from a field (or even from a ring).
Now take any 4 ⨯ 4 matrices and partition them into 2 ⨯ 2 matrices whose entries are 2 ⨯ 2 matrices. Since associativity has already been established for 2 ⨯ 2 matrices, the partition theorem and the above result establish associativity for 4 ⨯ 4 matrices.
Continuing in this way, we can establish associativity for arbitrarily large square matrices whose size is a power of 2.
Now consider the multiplication of two matrices A and B of any other shapes and sizes (that are suitable for multiplication, of course). Create two large square matrices whose size is a power of 2. Put A and B into their upper left corners and make all other entries zero. Then their product is a square matrix of the same size with the product AB in the upper left corner and zeros elsewhere. (The partition theorem can be used for this, but it can easily be verified directly.) Apply the same technique to three matrices to show that associativity of multiplication of the large matrices implies associativity for the smaller matrices in their upper left corners.
The direct sum of two or more square matrices (not necessarily of the same size) is a larger partitioned square matrix with the smaller matrices on its main diagonal and zeros elsewhere.
∣ A1 0 ... 0 ∣
∣ 0 A2 ... 0 ∣
A1 ⊕ A2 ⊕ ... ⊕ Am = ∣ * * * ∣.
Let V and W be two vector spaces over the same field. A function f:V ⟶W is a linear transformation (or function, or mapping) if it preserves the vector operations, i.e., for all vectors x and y in V and every scalar s,
The following properties are immediate:
The null space of a linear transformation f:V ⟶W is the set of all vectors that it maps to the zero vector {x ∈ V ∣ f(x) = O}. It is a subspace of V whose dimension (if it exists) is called the nullity of f. The dimension of the range of f (if it exists) is called the rank of f.
The following theorem is usually called the rank plus nullity theorem.
Theorem 4.1. f:V ⟶W be a linear transformation. If V is finite-dimensional, its dimension is the sum of the rank and nullity of f.
Proof. Since the null space of f is a subspace of V, it has a dimension k. Let v1, v2, ... vk be a basis for it.
Append the vectors vk+1, vk+2, ... vdim(V) to form a basis for V.
We need only show that the vectors f(vk+1), f(vk+2), ... f(vdim(V)) form a basis for the range of f.
Let f(x) be any vector in the range of f. Then x is expressible as
x = c1 v1 + c2 v2 + ... + ck vk + ck+1 vk+1 + ck+2 vk+2 + ... + cdim(V) vdim(V).
We apply f to both sides of the equation and simplify to obtain:
f(x) = c1 f(v1) + c2 f(v2) + ... + ck f(vk) + ck+1 f(vk+1) + ck+2 f(vk+2) + ... + cdim(V) f(vdim(V)).
Since the first k basis vectors are in the null space of f, this reduces to:
f(x) = ck+1 f(vk+1) + ck+2 f(vk+2) + ... + cdim(V) f(vdim(V)).
Hence any vector in the range can be expressed as a linear combination of the vectors f(vk+1), f(vk+2), ... f(vdim(V)).
Now consider an arbitrary linear combination of these vectors that equals zero:
O = dk+1 f(vk+1) + dk+2 f(vk+2) + ... + ddim(V) f(vdim(V)).
Since f is linear, this can be rewritten as:
O = f(dk+1 vk+1 + dk+2 vk+2 + ... + ddim(V) vdim(V)).
Hence the argument of f is in the null space of f and can be written as
dk+1 vk+1 + dk+2 vk+2 + ... + ddim(V) vdim(V) = e1 v1 + e2 v2 + ... + ek vk.
We can rearrange this to obtain:
-e1 v1 - e2 v2 - ... - ek vk + dk+1 vk+1 + dk+2 vk+2 + ... + ddim(V) vdim(V) = 0.
Since the vectors are a basis for V, all coefficients must be zeros. Hence f(vk+1), f(vk+2), ... f(vdim(V)) are linearly independent, which completes the proof. █
Suppose V and W have bases v1, v2, ..., vm and w1, w2, ..., wn, respectively, and f:V ⟶W is a linear transformation. Define an n ⨯ m matrix A whose j-th column contains the coefficients when f(vj) is expressed as a linear combination of the basis for W:
f(vj) = a1j w1 + a2j w2 + ... + anj wn.
Now consider an arbitrary vector x of V and its image f(x) in W, expressed in terms of the bases:
x = x1 v1 + x2 v2 + ... + xm vm.
f(x) = y1 w1 + y2 w2 + ... + yn wn.
The image f(x) can be also expressed as follows:
f(x) = x1 f(v1) + x2 f(v2) + ... + xm f(vm) =
x1 (a11 w1 + a21 w2 + ... + an1 wn)) +
x2 (a12 w1 + a22 w2 + ... + an2 wn)) +
... +
xm (a1m w1 + a2m w2 + ... + anm wn)) =
(a11 x1 + a12 x2 + ... + a1m xm) w1 +
(a21 x1 + a22 x2 + ... + a2m xm) w2 +
... +
(an1 x1 + an2 x2 + ... + anm xm) wn.
Since the expression is unique,
y1 = a11 x1 + a12 x2 + ... + a1m xm,
y2 = a21 x1 + a22 x2 + ... + a2m xm,
... ,
yn = an1 x1 + an2 x2 + ... + anm xm.
This is the definition for a matrix multiplication:
(y1, y2, ..., yn)T = A(x1, x2, ..., xm)T.
An equivalent way of expressing the relationship is
(y1, y2, ..., yn) = (x1, x2, ..., xm)AT.
Depending on the convention followed, either A or AT is called the matrix of the transformation with respect to the bases. We follow the first convention.
If V and W are spaces of column vectors, then the transformation can be written as f(x) = Ax, where A is the matrix relative to the canonical bases.
Let V, W and Y be vector spaces, and let f:V ⟶W and g:W ⟶Y be linear transformations with matrices A and B, respectively. If the same basis is used for W in each case, then the matrix of the composite linear transformation f ◌ g:V ⟶Y is BA or AB, depending on the convention followed. This can be proven directly, and then the associativity of composition can be used to prove the associativity of matrix multiplication.
If f:V ⟶ V is a linear transformation then a subspace W is said to be invariant under f if f carries W into (or onto) itself; i.e., if f(x)∈W for all x∈W. Then f:W ⟶ W (the restriction of f to W) is also a linear transformation.
If a finite-dimensional vector space is a direct sum of two or more subspaces, then bases for the subspaces may be combined into a basis for the whole space. If all subspaces are invariant under a linear transformation, then the matrix of the transformation, relative to the combined basis, is easily seen to be the direct sum of the matrices of the transformation on the individual subspaces.
An n ⨯ n matrix A defines a linear transformation from the vector space of n ⨯ 1 column vectors to itself:
f(x) = Ax.
The rank of the matrix is the rank of the transformation. The matrix is said to be singular if its rank is less than n.
Clearly, the zero matrix is singular and the identity matrix is nonsingular.
There are a number of other conditions for singularity of a matrix, all of which are equivalent. Here are some of them; we will add more later.
| The n ⨯ n matrix A is singular if-- | The n ⨯ n matrix A is nonsingular if-- | |
|---|---|---|
| 1 | the rank of A is less than n | the rank of A is n |
| 2 | there is a vector y such that Ax ≠ y for every vector x i.e., the associated linear transformation f is not onto | for every vector y there is a vector x with Ax = y i.e., the associated linear transformation f is onto |
| 3 | the associated linear transformation f is not one-to-one | the associated linear transformation f is one-to-one |
| 4 | Ax = O for some x ≠ O | Ax = O implies x = O |
| 5 | The columns of A are linearly dependent | The columns of A are linearly independent |
| 6 | AT is singular | AT is nonsingular |
| 7 | The rows of A are linearly dependent | The rows of A are linearly independent |
The first four conditions can be shown to be equivalent by dimensionality arguments and the rank plus nullity theorem.
The product Ax is a linear combination of the columns of A with coefficients taken from x. Hence Ax = O for some x ≠ O if and only if the columns of A are linearly dependent. Hence the fifth condition is equivalent to the first four.
Now assume that A is nonsingular according to the second condition, and let y be a column vector with ATy = O. Then (ATy)T = yTAT is a zero row vector, so yTATx = 0 for every vector x. Choose x so that ATx = ei, the column vector with 1 in its i-th row and zeros elsewhere. Then yTATx = yi, the entry in the i-th row of y. Hence every entry in y is zero, and AT is nonsingular by the third condition.
Since AT T = A, the same line of argument proves the converse.
The last condition is equivalent to the others because the rows of A are the columns of AT.
Theorem 5.1. The product of two or more square matrices of the same size and over the same field is nonsingular if and only if all factors are nonsingular.
Proof. First assume that A and B are nonsingular and (AB)x = O. Since matrix multiplication is associative, A(Bx) = O. Since A is nonsingular, Bx = O. Since B is nonsingular, x = O. Hence AB is nonsingular.
Now assume that B is singular. Then Bx = O for some nonzero vector x. Hence ABx = O and AB is singular.
Now assume that A is singular but B is nonsingular. Then Ax = O for some nonzero x and By = x for some nonzero y. Hence Ax = ABy = O, so AB is singular.
The extension to products of three or more matrices is straightforward. █
A square matrix A may have an inverse A-1 for which AA-1 = I, the identity matrix of the same size.
Theorem 5.2. A square matrix has an inverse if and only if it is nonsingular.
Proof. If a matrix has an inverse, Theorem 5.1 shows that it must be nonsingular.
Now assume that A is nonsingular. Then for every i, there is a column vector xi such that Axi is the i-th column of the identity matrix A of the same size. Let B be the square matrix of the same size whose columns are x1, x2, x3, etc. The partition theorem shows that AB = I, so B is the required inverse. █
An elementary row operation matrix E(i,j,c) is nonsingular; its inverse is E(i,j,-c).
Matrix multiplication is not commutative in general, but every nonsingular square matrix commutes with its inverse. If A is nonsingular, so is its inverse. Consider the product A-1AA-1(A-1)-1, associated in two ways:
A-1(AA-1)(A-1)-1 = A-1I(A-1)-1 = A-1(A-1)-1 = I ,
(A-1A)(A-1(A-1)-1) = (A-1A)I = A-1A .
The rank of a matrix A is defined to be the rank of the linear transformation defined by f(x) = Ax, even if the matrix is not square. That is, it is the dimension of the range {y ∣ y = Ax for some vector x}.
Theorem 6.2. If P and Q are nonsingular matrices, then the rank of PA and AQ are equal to the rank of A.
Proof. The range of PA is the image of the range of A under the linear transformation associated with P. Since P is nonsingular, this is an isomorphism and preserves dimension. Hence the ranks are equal.
Consider the ranges of A and AQ. If Ax is in the range of A, then the same vector, written as AQ(Q-1x), is in the range of AQ. If AQx is in the range of AQ, the same vector, written as A(Qx), is in the range of A. Hence A and AQ have the same range and the same rank. █
There are two other ways to define the rank of a matrix. The row rank is the maximum number of linearly independent rows, and the column rank is the maximum number of linearly independent columns. We shall show that all three ranks are equal.
Theorem 6.2. The rank, row rank and column rank of any matrix are equal.
Proof. The column vector Ax is a linear combination of the columns of A with coefficients taken from x. Hence the range is the space spanned by the columns, and its dimension is obviously the column rank.
Now let r be the row rank of A and rearrange the rows so the first r rows of A are linearly independent, which clearly does not change either the row or column rank of A.
Since the last rows of A are linearly dependent on the first r rows, perform elementary row operations to make all rows except the first r identically zero. Since each operation is performed by multiplying A by a nonsingular matrix, the process does not change the column rank.
Now consider any r+1 columns of A. All entries in any but the top r rows are zeros. These top portions form a set of r+1 r-dimensional vectors, which must be dependent. The same dependency shows that the whole columns are dependent. Hence the column rank of A cannot exceed its row rank.
The same line of argument applied to AT shows that the row rank of A cannot exceed its column rank. Hence the row and column ranks must be equal. █
A submatrix of a matrix is obtained by choosing one or more rows and one or more columns, deleting all other rows and columns, and pushing the remaining entries together to form a possibly smaller matrix. The submatrices used in the partition theorems are special cases in which the chosen rows and columns are consecutive. A submatrix of a submatrix is also a submatrix of the original matrix.
This gives us another definition of rank.
Theorem 6.3. The rank of a matrix is the size of its largest nonsingular square submatrix.
Proof. Let r be the rank of the matrix according to previous definitions. Then there are r linearly independent rows. Choose them and delete the others to form a submatrix of rank r with r rows. The column rank of the submatrix is also r, so it has r linearly independent columns. Choose these columns to obtain an r ⨯ r square submatrix of rank r, which is nonsingular.
Now consider any square submatrix larger than r ⨯ r. The columns taken from the original matrix must be linearly dependent, so there is a nontrivial linear combination of these columns that evaluates to the zero vector. The same linear combination, when applied to the rows in the submatrix, evaluates to the zero vector and shows that the submatrix is singular. █
Suppose an n-dimensional vector space has two bases:
v1, v2, ..., vn,
v'1, v'2, ..., v'n.
A vector can be represented uniquely as a linear combination of either basis:
x = x1v1 + x2v2 + ... + xnvn,
x = x'1v'1 + x'2v'2 + ... + x'nv'n.
Clearly, a transformation that carries the coefficients x1, x2, ..., xn into x'1, x'2, ..., x'n is linear, so it has a matrix R. Because the transformation is one-to-one, the matrix has an inverse R-1. In fact, the entries in R or R-1 are simply the coefficients when the vectors in one basis are expressed as linear combinations of the vectors in the other basis. Depending on the particular convention being used, R, R-1, RT or (R-1)T may be called the matrix of the basis change.
Let A be the matrix of any linear transformation relative to the second basis. The matrix of the same transformation relative to the first basis is easily shown to be R-1AR.
Two square matrices related in this way are said to be similar.
Since similar matrices represent the same linear transformation, (1) they have many properties in common, which are properly described as properties of the transformation, and (2) similarity is obviously an equivalence relation. However, the properties of equivalence relations, such as transitivity, can be verified through matrix operations alone:
B = R-1AR,
C = S-1BS,
C = S-1(R-1AR)S = (S-1R-1)A(RS) = (RS)-1A(RS).
Similarity with respect to the same basis change also preserves matrix operations:
c(R-1AR) = R-1(cA)R,
(R-1AR) + (R-1BR) = R-1(A+B)R,
(R-1AR)(R-1BR) = R-1(AB)R.
Hence addition, multiplication and scalar multiplication of square matrices can be properly considered operations on the associated linear transformations.
A square Vandermonde matrix is a matrix of the following form:
∣ 1 e1 e12 ... e1n-1 ∣
∣ 1 e2 e22 ... e2n-1 ∣
∣ 1 e3 e32 ... e3n-1 ∣
***
∣ 1 en en2 ... en-1n-1 ∣
Theorem 8.1. A square Vandermonde matrix is nonsingular if, and only if, the elements of its second column are all different.
Proof. If two elements of the second column are identical, the matrix has two identical rows and is singular.
Now assume that e1, e2, ..,, en are all different in the square Vandermonde matrix show above. Suppose a linear combination of its colums is zero, i.e.,
c0 + c1e1 + c2e12 + ... + cn-1e1n-1 = 0,
c0 + c1e2 + c2e22 + ... + cn-1e2n-1 = 0,
c0 + c1e3 + c2e32 + ... + cn-1e3n-1 = 0,
***
c0 + c1en + c2en2 + ... + cn-1enn-1 = 0
Then the polynomial
c0 + c1z + c2z2 + ... + cn-1zn-1
has n distinct roots and degree less than
n, which is possible only if
c0 = c1 = c2 = ... = cn-1 = 0.
Hence the columns of the matrix are linearly independent and the matrix
is nonsingular.
█
Links